(H1235 - Maximum Profit in Job Scheduling) O(N^2) DP binary search 최적화
O(N^2) basic DP를 binary search (lower_bound)를 활용해서 O(NlogN)으로 최적화 할 수 있는 문제.
배운점 :
- 정렬된 상태에서 시간 줄여야 한다면 → binary search 고려
- constraint 걸어주는 아이디어
Sol 1

Step 1) basic DP O(N^2)
startTime을 오름차순으로 정렬.
dp(i) : i번째 job을 선택했을때 max profit (남은 조각에 대한 답을 반환)
i 이후의 valid한 job만 고려.
이 풀이의 문제는, i이후의 dp값을 모두 체크하며 그 중 max값을 찾아야 함. O(N^2)
Step 2) lower_bound로 search 시작지점 최적화 ~ 여전히 O(N^2) worst case
그러나, i 다음의 i+1이 바로 valid 하지 않을 수 있음.
lower_bound 써서 바로 valid 한 job부터 찾을 수 있겠다고 생각 (j라고 하자)
그래도 여전히 j부터 N-1까지 탐색하므로, worst case O(N^2)은 변치 않음.
Step 3 - 끝 지점 최적화
search 시작하고, 이미 앞의 memo에 의해 방문당한 job에 도달하면 바로 break (minEnd 시간 기록해나가며)
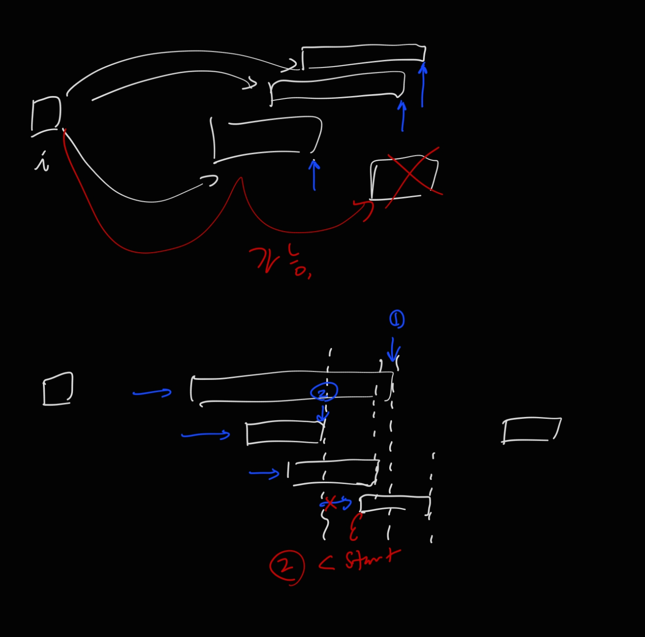
위 그림에서 보듯이, X쳐진 job은 첫번째 valid job에 의해 이미 방문되었을 것임.
i입장에선 이제 더 탐색할 이유가 없음
이런걸 어떻게 찾냐?
valid job들의 endTime중 최솟값을 tracking하다가, 이 값보다 큰 start를 가지는 job이 나오면 탐색을 종료.
이제 나머지 job들을 모두 방문할 필요가 없으니, constant time이 걸릴 것으로 예상됨.
O(NlogN)
FORd(i, N - 2, 0) {
int idx = jobs[i].second;
auto startIt = next(jobs.begin(), i + 1);
pii key = { endTime[idx] , -1 };
auto it = lower_bound(startIt, jobs.end(), key);
int j = distance(jobs.begin(), it);
// Search jobs only on first visit - no duplicate searches
int minEnd = INF; // ★ minimum endtime among valid jobs
for(; j < N; j++){
int jdx = jobs[j].second;
minEnd = min(minEnd, endTime[jdx]);
if (minEnd < jobs[j].first) break; // already visited by prior valid job
if (endTime[idx] > jobs[j].first) continue;
dp[i] = max(dp[i], dp[j] + profit[idx]);
}
}
Sol 2 - (해설) 앞에서부터 시작
binary search를 좀 더 확실하게 사용한 기발한 풀이를 찾아서 정리함.
dp(time) : time 까지의 max profit
즉, endTime 오름차순으로 정렬 후, 앞에서부터 처리해나가는 방식.
이 방식은 중복탐색을 어떻게 처리했을까?

j라는 job을 고려할 때, 파란색으로 체크된 previous valid job들을 하나씩 체크해야 함.
저 체크의 마지막을 i라고 할때, 이건 binary search로 바로 찾기 가능
(여기까진 내 풀이와 동일)

그런데, 생각해보면 0~i 모두를 고려할 필요가 있을까?
만약 dp[i-1] < dp[i] 임을 보장해준다면, 가장 마지막에 있는 i만 고려하면 될 것임.
현재 job의 endTime이 t라고 할때, dp(t)도 바로 직전의 dp값보다 작다면 업데이트 하지 않도록 코드 짜준다.
for (pii& p : jobs) {
auto [t, idx] = p;
int pft = prev(dp.upper_bound(startTime[idx]))->second + profit[idx];
// ★ 중복 탐색을 막아주는 핵심 - max 갱신한 결과만 저장한다
// = dp에 저장된 마지막 원소 (dp.rbegin()->second)가 max값
if (dp.rbegin()->second < pft)
dp[t] = pft;
}
'BOJ 15486 - 퇴사2'가 이 문제랑 같더라 (매일 시작하는 job이 따로 있고, 끝나는 시간이 다 다름)
'<PS> > [복기 - LeetCode]' 카테고리의 다른 글
| (224 - Basic Calculator) 사칙연산 + 괄호 식 parsing (0) | 2021.09.17 |
|---|---|
| (H312 - Burst Balloons) DP 이전정보 + reverse thinking (0) | 2021.08.19 |
| (H546 - Remove Boxes) DP 이전정보 처리하기 ★ (0) | 2021.08.17 |
| (H1632 - Rank Transform of a Matrix) 순서 강제 + Union-Find (0) | 2021.08.12 |
| (H-827 Making A Large Island) 단순 채우기 BFS 재귀 코드 (0) | 2021.08.02 |